Upgrading Apache Flink
I wanted to upgrade my Flink version for a while now. I was running on a 1.2 Snapshot which I had extended with some monitoring functionality (during Digital Ocean’s Hacktoberfest last year I decided to submit a few pull requests to improve Flink’s monitoring capabilities and I was running on this branch ever since). The goal I set was to upgrade to the latest Flink release which at the moment should be 1.3.2.
First I wanted to do some testing locally with the new release. Upgrading the Flink version was quite easy, it only involved changing the flink.version tag in pom.xml (actually before I could do that I had to upgrade my local branch with what was in the upstream).
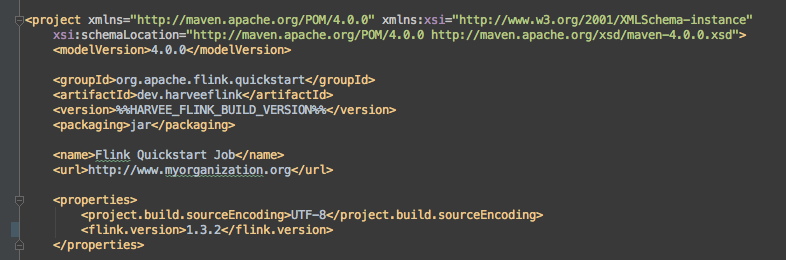
Maven was taking care of most of the dependencies and upgrades of libraries, however in my setup I am using Kinesis (instead of Kafka) and the Flink Kinesis Connector has a dependency on code licensed under the Amazon Software License (ASL) which is why the connector is not available as an artifact from the Maven repository.

To create the connector one has to build it from the source. This explains what has to be done.
For testing Flink I have to start a few Docker containers locally. In production the Flink jobs connect to AWS Kinesis but locally I am using a container running Kinesalite which is written in NodeJS to mimic Kinesis for testing purposes. My Flink jobs take data off a Kinesis or Kinesalite stream, map and reduce it and then send it to a PostgresDB, ElasticSearch cluster and a Neo4J instance so I have Docker containers running for these locally as well.

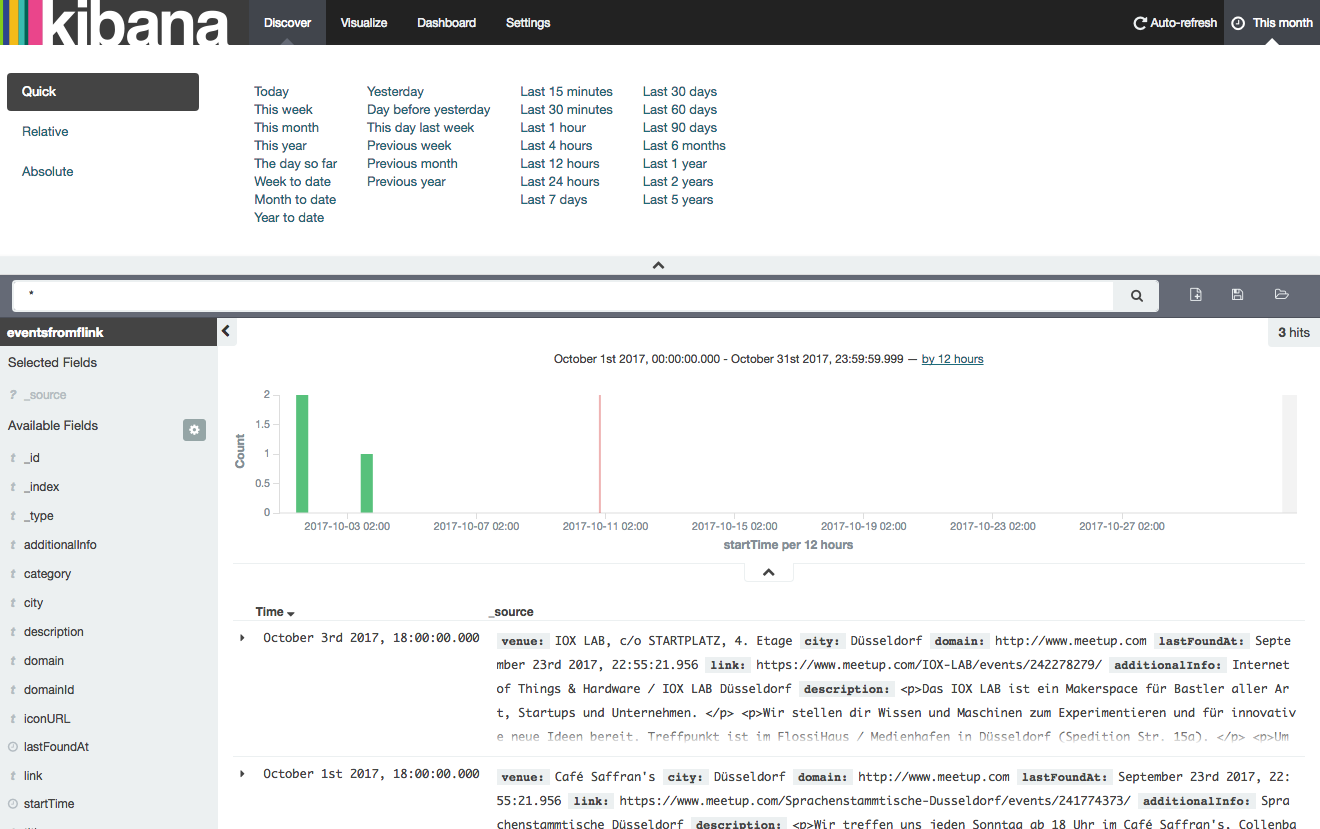
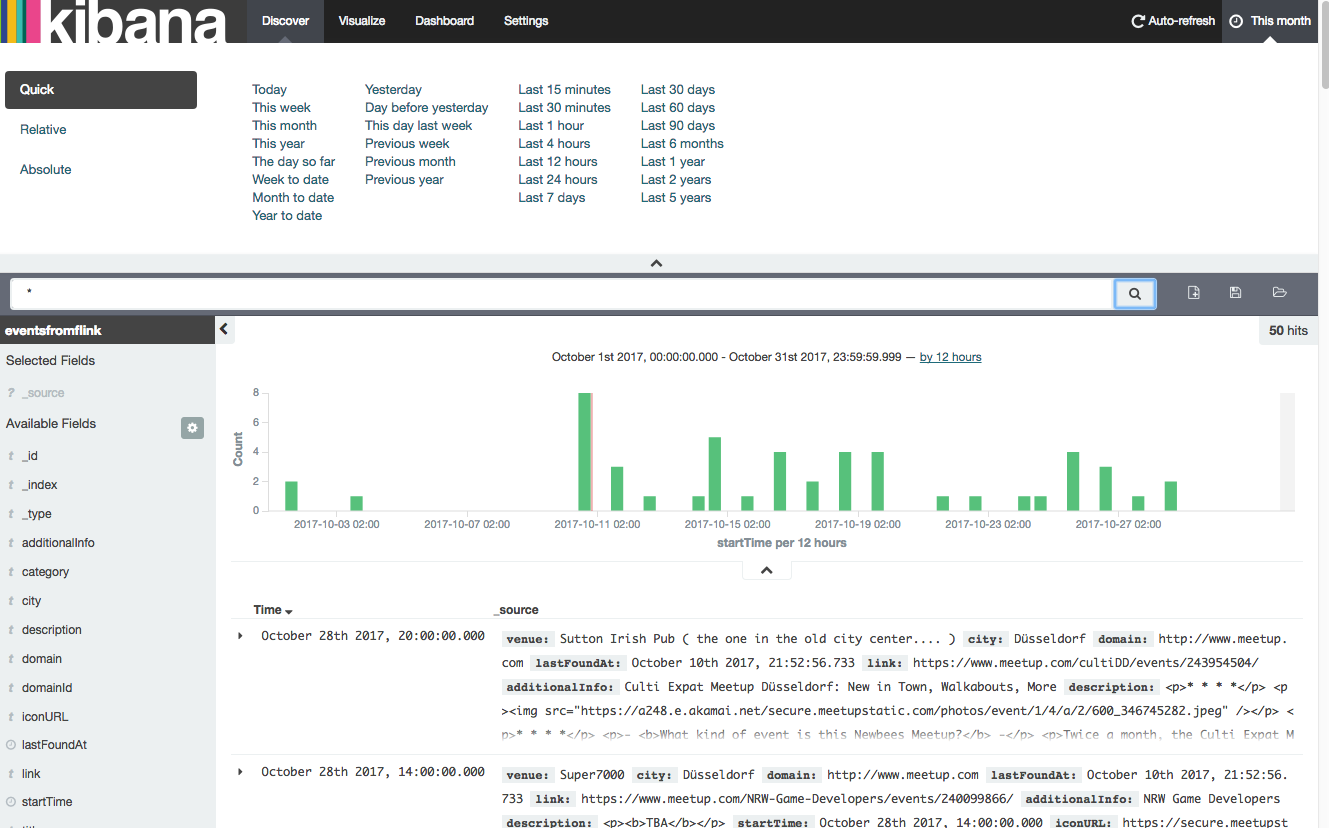
The data that is put on Kinesis/Kinesalite comes from Scrapy spiders and a client for the Meetup API and I typically run the client for Meetup locally to produce some data. In order to verify that my jobs were still doing their work as expected I had a look inside the Kibana UI sitting on top of ElasticSearch and verified for the current month if anything was added to the index after the test ran and indeed data was ingested so for me that was a good enough test verifying that my Flink jobs would still run on the new version.
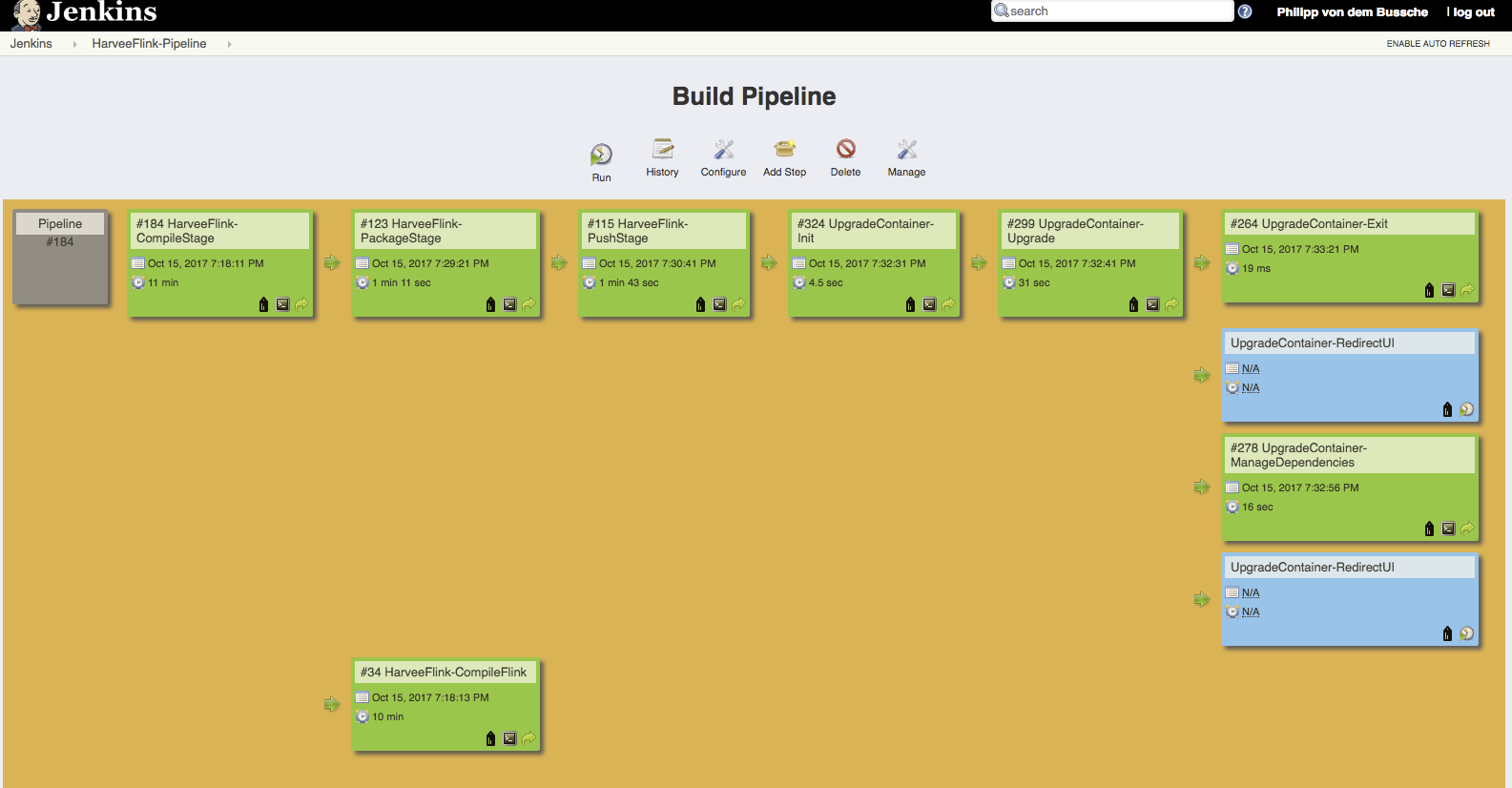
Upgrading Flink locally was the easy part however. My Flink estate outside the development environment is built automatically through different jobs on a Jenkins server but as I had to realise it wasn’t really setup in a way that would easily allow for updates of the Flink distribution (it was basically setup to deploy new versions of the job classes). I actually had to draw a little diagram of what the current build process looks like and with that I was able to identify what was missing for an upgrade of all Flink components involved.
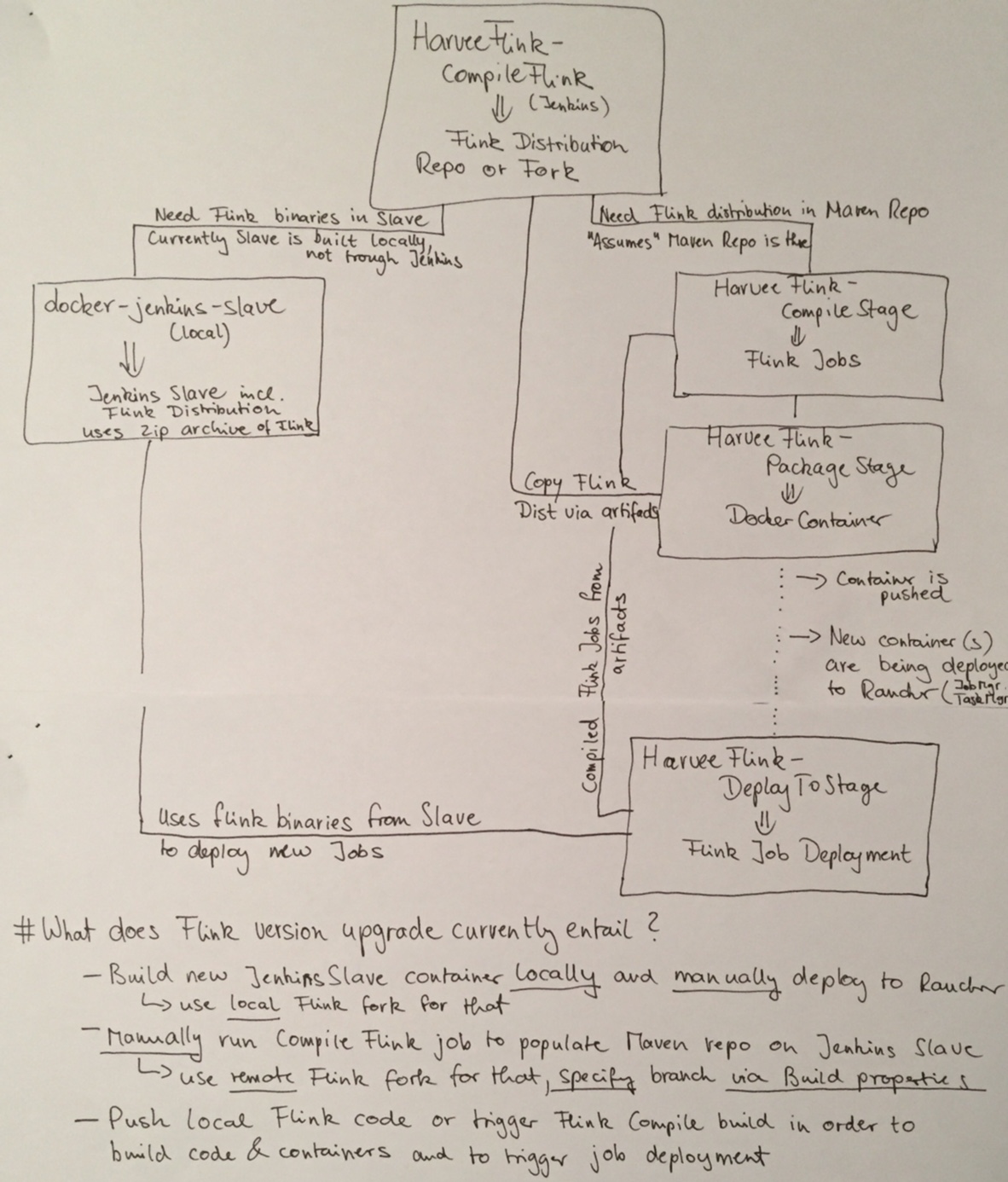
First of all although building Flink was done by a Jenkins build job it had to be triggered manually and the version of Flink to be built was sitting as a static parameter in the job definition. By building Flink the Maven repository on the Jenkins slave would get populated and ready to actually build the Flink job classes. The build of the job classes was however triggered separately and there was no dependency or check defined that would ensure a Flink distribution with a certain version was available.
One of the last steps of the build process for the Flink job classes is to deploy them onto a running Flink task manager and for this a Flink client with the right version is required. This deployment was obviously also done by the Jenkins slave so it needed that Flink client and for this I had updated the Jenkins slave (also a Docker container running on my staging server) whenever I had manually built a new version of Flink. This was the second thing that I did not quite like about the current setup.
What I therefore changed in my build process was that every start of a job build would first of all trigger a build of the Flink distribution. Since the Flink version number which the job was developed with is in the job’s pom.xml I added a build step that would execute python code in a bash in order to extract the version from there.
flink_version=python -c 'import xml.etree.ElementTree as ET; tree = ET.parse("pom.xml"); root = tree.getroot(); print root.find("{http://maven.apache.org/POM/4.0.0}properties").find("{http://maven.apache.org/POM/4.0.0}flink.version").text;'
The only contract or dependency that is still in place is that a Flink distribution with a tag as specified in the pom.xml has to be available in my fork of the Flink distribution but I thought this would be something that should always be satisfied. Since I am now building a complete Flink distribution with every new push of a job class I was keen to optimise the time it would take to build the Flink distribution. Starting at 25 minutes I was able to bring it down to 8 minutes with test compilation and execution disabled.
After building Flink the build process is taking its normal course right up to the point where the job classes would be deployed onto the task manager. Instead of expecting the Jenkins slave to have a suitable Flink client in place I made sure that the Flink distribution built in the beginning (which would contain a client) was available as an artifact later on so it can be copied into the last step of the build and be used to deploy the job classes.
I am quite happy with the setup I ended up with in the end. Below is a screenshot of the new and redesigned build process.