Serverless – Getting The Basics In Place
It feels like I have to take a step back and explain to the audience of my blog how data is actually travelling through Harvee. I want to focus on the process of picking up the data, massaging it and then storing it. The following steps describe how this is accomplished:
- A python program leveraging the Scrapy framework and another python program accessing the Meetup API capture the events for Düsseldorf and push them onto a Kafka topic.
- An Apache Flink job consumes the events and pushes them into an ElasticSearch cluster.
- For inventory purposes the job also pushes (some of) the data into other sinks (normalized data goes into a Postgres database, events and venues and their interdependencies end up in a Neo4J graph).
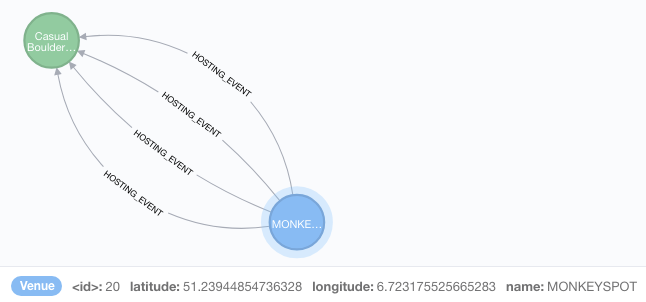
The graph will be the basis of the Serverless/AWS Lambda implementation. As mentioned it stores event and venues and in Neo4J terms these are modelled as nodes. An event node does not contain the date when it is actually happening, this is stored as a relationship. There might be multiple relationships between an event and a venue because events might be reoccuring (a theatre performance might be shown every day of the week).
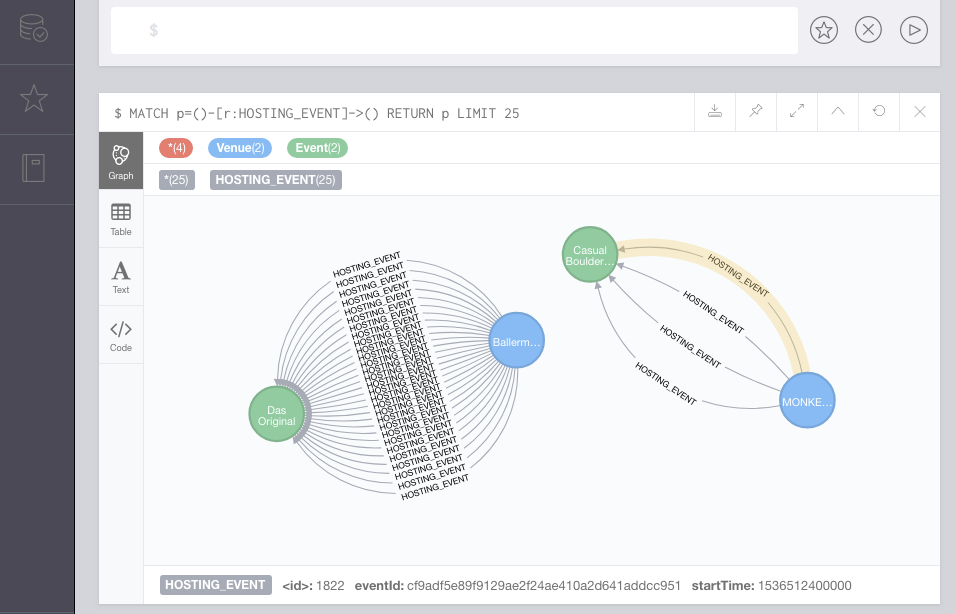
In order to calculate the distance between venues and suggest other events happening close by (which is what the Lambda proximity search function is supposed to do later) it is required to know at which coordinates a certain venue is placed. When the data comes back from the Meetup API it contains this information already, but not all data scraped from websites will contain geo coordinates. To make sure the coordinates are available for all venues an asynchronous process was introduced for the Apache Flink job consuming the events to run all venues without coordinates against the Foursquare API and get that data back.
public class AsyncFoursquareRequest extends RichAsyncFunction { ... }
Calculating the distance between venues who carry coordinates is easily done in Neo4j e.g. using spatial functions, which requires the longitude and latitude to be set as labels for each node.
To be able to expose the graph data on the Internet for the AWS Lambda function to access it an additional Hetzner cx11 cloud server was provisioned which is running the Neo4J database in a container (orchestrated by Rancher).
The last open item was now to make sure the data is fed into the Neo4j database running in the cloud. So far the event processing and population of inventory data was tightly coupled meaning the inventory processing would be directly triggered from within the Flink event job. The design had to be changed to introduce another topic on Kafka where only inventory related data is pushed into from the events job. There are now multiple (additional) inventory jobs (one per environment) consuming data and pushing it further into the respective environment (which includes an on-premise Neo4J database for preproduction and the production one in the Hetzner cloud).
Having a Neo4J database exposed to the Internet with data including geo coordinates forms the basis for my serverless function to be implemented, which I will explain in the next blog entry.