Getting To Know Microservices – Writing A Microservice
It was time now to actually write a microservice, after building the API gateway and making sure that I can (as part of the build pipeline) add the necessary changes when new (versions of my) microservices are coming online. I know that these days a lot of developers implement their services in languages like NodeJS. However, I decided to stick with Python and continue to use Django as well as the Django REST framework as a basis. I understand that Django is actually quite rich and some might consider it an even heavy choice to write a microservice, then again I quite like the structure it gives one while developing the code (I felt a bit lost when using Flask before as it did not seem to define any structure which resulted in my code to become very unattractive).
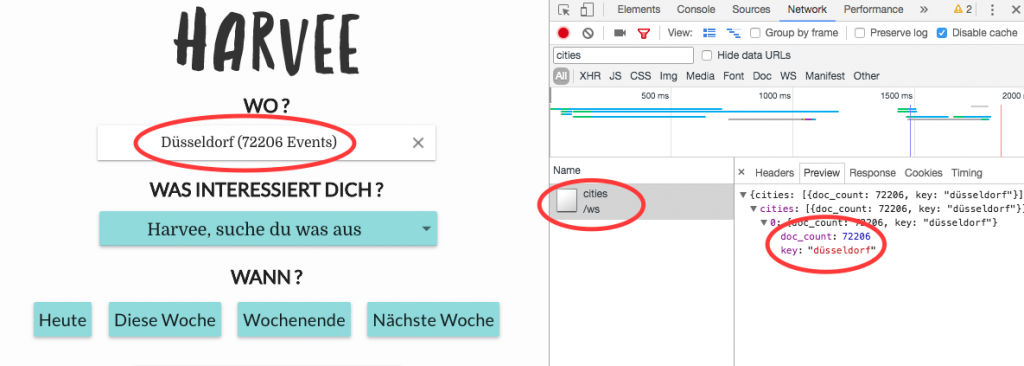
As my first microservice I decided to implement the “cities” service (Note: while planning this initially I had something else in mind but hey this is agile !). Even though I currently only capture events happening in Düsseldorf this could change in the future so the “cities” service would store all the cities that I am able to serve. The list of cities as well as an event count per city is loaded on the search page of Harvee so the first function that I wanted to implement in the service was to get an event count per city.
Besides the actual functionality I am also adding deployment related configs and code in the microservice repository.
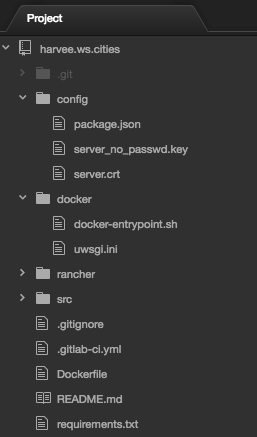
I defined a file (package.json – sorry for stealing this from the NodeJS folks !!) which allows me to set the URI under which this microservice should be made available when deployed (this is read while building and the route on the API gateway is set accordingly).
{
"uri": "/ws/cities"
}
Also a Dockerfile is part of the repository, which defines how a container would be built for the microservice. I designed the structure to be as generic as possible. I believe that this format can also be used for any other microservice that might come in the future. Some explanations on my Dockerfile:
I am using an alpine based image available from the python repository:
FROM python:3.6.4-alpine3.6
I am installing uwsgi which will be used to serve the Django app later and whatever was defined in requirements.txt is going to be installed also:
RUN apk add --update --no-cache gcc libc-dev linux-headers && \
pip install https://github.com/unbit/uwsgi/archive/2.0.17.zip#egg=uwsgi && \
pip install -r requirements.txt && \
mkdir /service
I decided when calling the microservice with the OPTIONS http method that I want to return more details on the microservice including the version, from which branch it resulted as well as the name of the stack it is part of in Rancher. Those information will be provided using –build-args when the container is built and then made available to the Django app via environment variables:
ARG version=1
ARG branch=master
ARG stack=stack
ENV version ${version}
ENV branch ${branch}
ENV stack ${stack}
Taking the code, building the container with all required libraries and deploying it as well as making it available through its designated URL on the API gateway is a task for the build tool. As written in my last blog article I had a look at Gitlab and decided to use it going forward. This means my repository now also contains a .gitlab-ci.yml which defines how the repository will be built. Again I believe the different stages are quite generic and I want to explain them a bit more in detail here:
Since my Gitlab worker is a Docker container and I am using other containers throughout the various build stages I am making use of the Docker-In-Docker (dind) paradigm:
services:
- name: docker:17.09-dind
I am using three stages in my build pipeline. First a container will be built (build) with the app’s sources, secondly the container is deployed (deploy) to my Rancher estate and thirdly the API gateway routes are being configured (register):
stages:
- build
- deploy
- register
In the deploy as well as register stage I am executing build scripts through specialised containers. The following shows how I am achieving to register the service at the API gateway:
.register_script: & register_script
stage: register
image: myrepository/carl:latest
before_script:
- export kong_uri=cat config/package.json | jq -r .uri``
script:
- export stack="${service_name}-${CI_COMMIT_REF_SLUG}-${CI_COMMIT_SHA:0:8}"
- export command="carl update_api --server $kong_admin --strip_uri false --uri $kong_uri --upstream_url http://proxy.$stack --host $kong_target_host --client_ssl true --cert $kong_cert --key $kong_key"
- eval $command && echo $command > createKongApi.${service_name}.${CI_COMMIT_SHA:0:8}.sh
- carl dump_apis --server $kong_admin --client_ssl true --cert $kong_cert --key $kong_key > createKongApi.${CI_COMMIT_SHA:0:8}.sh
artifacts:
paths:
- createKongApi.${service_name}.${CI_COMMIT_SHA:0:8}.sh
- createKongApi.${CI_COMMIT_SHA:0:8}.sh
I want to add some explanation around some of the above configuration: YAML has the concept of anchors which is also supported in Gitlab runners. Using this I can re-use build instructions. The above register section is being used for both builds for the master as well as production branch. However, certain environment variables will be set to different values depending on the branch (e.g. $kong_admin points to different hosts depending on the branch as the master branch only ever gets deployed to my stage environment and only the production branch ends up in the production environment). I have built a container that contains “carl” which I also spoke about in a previous post (carl helps me to interact with Kong – which is my API gateway). Two carl commands from a container are executed as part of the build. The first one creates or updates the API routing, the second one dumps all API configuration from the gateway. The build script above produces artifacts (createKonApi.*.sh) as the result of calling the carl utility. The first file contains only the carl instruction executed as part of this build whereas the second file will contain all API configuration configured on the gateway. With this I am hoping to be able to restore specific or all configuration on the API gateway in case something gets lost.
After a successful production build run the new microservice container will show up in my Rancher estate.
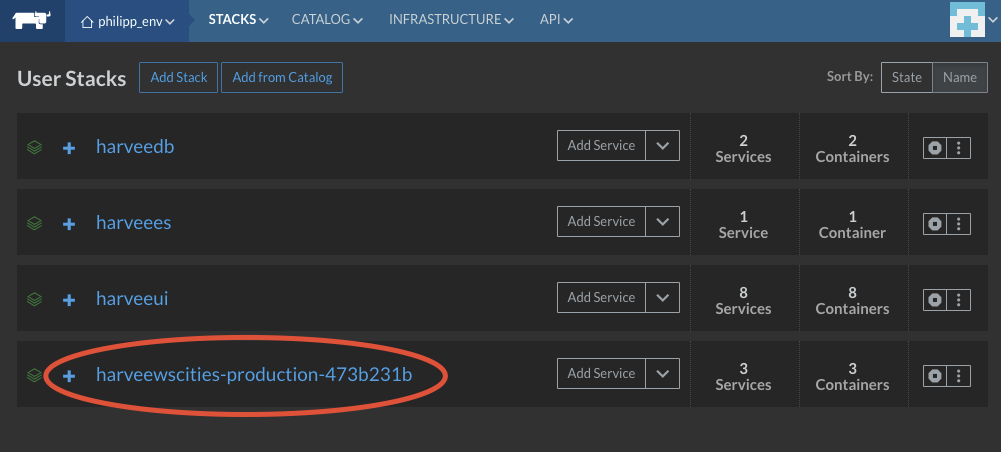
Obviously only the next microservice will show if I can re-use the configuration I have found. Also there are some unanswered questions still at this point: since I am continously deploying containers I will at some point have a huge list of containers which are not used anymore (I realistically only need the previous container version really) which means that I need to find a way to dispose them after a while. Also I need to feed back the definition of deployed containers into my bootstrap scripts which I am using to automatically build new environments from scratch (e.g. when I am moving cloud providers). Still I am quite hopeful that this will be a good initial setup going forward.