The Cloud And The Spend
I am spending about 55$ each month for the services on AWS I am using to run Harvee. While I am happy with the total cost it always felt that the 35$ I am paying „only“ for using the Elasticsearch Service in AWS was a bit high compared to the remaining costs, which are basically charges for computing in EC2.
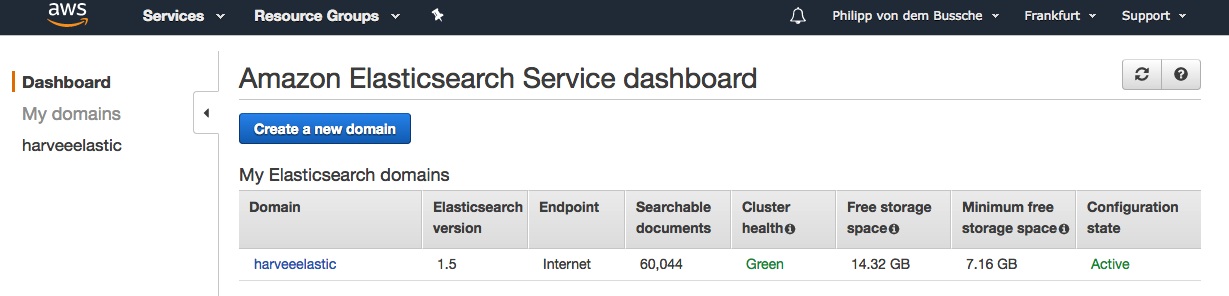
I never really changed my Elasticsearch setup since the inception of Harvee about 2,5 years ago so still I have one domain consisting of two instances (t2.micro.elasticsearch). This results in a GREEN Elasticsearch cluster with two data nodes currently hosting about 60k of documents (which would translate into 60k of events discovered and available to users through Harvee). Btw. as far as I know the cluster was GREEN since it got created so I can’t complain about the quality of the service at all.
Still I wanted to explore my options to reduce the costs for running Elasticsearch. I read a few articles on the advantages of managing an Elasticsearch cluster yourself. People were pointing out that you would not be tied to the release version available in AWS but instead you could basically run the latest and greatest from Elastic. For me this wasn’t really required as the features available in version 1.5 were still sufficient (I guess I should apologize for having to say this). At the end of the day I was only interested in bringing down the amount of my spend and as you will read I was taking a few decisions in order for spenditure to go down. Disclaimer: the idea was not to completely say good bye to Amazon for hosting my data. The plan was to manage ElasticSearch myself but on EC2 infrastructure so I would just use Amazon’s computing and build everything else myself on top of that.
Since I am running all of the software required for Harvee in containers it would have been more than easy to use an existing Elasticsearch image and power up an environment. I realized quite quickly though that if I would manage this myself I had to take care of a few things where the most critical seemed to be access control.
As you can see in the tech section of my website I am using Rancher to orchestrate my containers. One of the advantages of doing that is that Rancher will create an overlay network between the containers and secure the connections between them through IPSEC. For that matter even if you have components (like the webservice getting data out of Elasticsearch) on different (physical/virtual) hosts, the secure network will make sure only the containers part of your Rancher estate are able to communicate. This is great since you could run Elasticsearch in an unsecure way allowing non-authenticated access on the default http port. For me this doesn’t quite work however since the data ingestion into Elasticsearch is triggered from outside the Rancher world. The process which is scraping the various websites and APIs is running from my Intel NUC server at home (there are scrapy pipelines who service the production as well as staging environment) so in order to ingest the data into the Elasticsearch instance for my production setup this would require a connection from the Internet. Apparently Elastic has ways to secure your deployment which in pre 5.x versions was called Shield and now moved into X-PACK. However there seems to be a license cost involved if you would want to use it.
When using Elasticsearch from AWS you can rely on the same IAM features as you have with any our their services so you can configure your role based access for the service. For connections coming from the Internet you have things like SSL included. In turn that means that if I wanted to manage Elasticsearch myself I had to spend time on designing a solution that would also take care of the security aspects and close any security holes when exposing Elasticsearch to the Internet (since I did not want to pay for either Shield or X-PACK).
So let’s now look at an example from my python based tooling on how I would typically create a connection to the ElasticSearch service running in AWS.
def createConnectionToAWS(self, awsEndpoint, awsAccountId, awsSecretKey, awsRegion):
host = awsEndpoint
auth = AWS4Auth(awsAccountId, awsSecretKey, awsRegion, 'es')
es = Elasticsearch(
hosts=[{'host': host, 'port': 443}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
return es
As you can see (sorry for the camel-case notation – I am originally a Java programmer) the connection gets signed with an AWS4Auth object built on top of the access and secret key. With this authentication is taken care of. If you want to learn more about it have a look here. Also the connection is made to an SSL-enabled port which ensures encryption of the data. With me setting up my own ElasticSearch service this would be the two aspects to focus on: data encryption and sender authentication (making sure only I was pushing and pulling data into and out of the cluster). I finally came up with the following solution (other than previously I decided to only briefly describe my solution here, this is for security reasons of course 😉 )
- T2 small instance in EC2
- Webserver terminating SSL connection on „unusual“ port
- Webserver configured to only allow clients to connect that had authenticated using a client SSL certificate (I used this article for inspiration)
- Mechanism to ban clients which repeatedly tried to connect to ES without properly authenticating
- ElasticSearch installed in version 2.4
- Weekly snapshots to S3 triggered by cron
I was initially mentioning that my main goal with this excercise was to explore a way to save on costs and that I would possibly prioritise this before other things. One of the areas which hasn’t received much attention yet e.g. is availability. At this point I am running a single Elasticsearch node, which basically means there isn’t a cluster at all. I am well aware that with this my Elasticsearch cluster state will only ever be yellow and in case of the one node becoming unavailable I won’t be able to serve my application. Also I expect the security precautions I took not to be as sophisticated as AWS is providing it. There are companies which have made it their business to officially issue and sign SSL certificates and they obviously tell you your connections won’t be safe without it. Still this would mean additional costs which in case of the certificates should not be underestimated.
So considering security as well as availability aspects and how this is provided in AWS when using a service it might not be after all that I would really be saving on costs if I would try to build an equal solution (I might not be able to build it all myself actually). I am happy however with what I have running on EC2 currently and will (at least for a while) switch off the ElasticSearch service to see how my own instance is doing over time.