I live in Düsseldorf now for more than 10 years and I enjoy a great variety of free-time activities here.
While working as an IT architect I am helping customers to deploy systems, which they use to create better digital experiences for their businesses. However in my opinion IT should also help in our daily lifes. I want to provide a platform through which people, who enjoy a good time, can easily find events in Düsseldorf. It is important to me to incorporate local events as well as venues into the search.
I want to solve the following problems with my platform:
- in order to find events you have to manually browse over a number of individual websites like Facebook, regional event websites, sites from venues and event organizers, etc.
- one needs to find out where to start searching in the first place
- one needs to expose too much personal data while searching
I created Harvee for all of these reasons: a platform that crawls events on the internet which are made accessible through a central interface (without asking too many questions).
Please see below if you are interested in the technical details of the implementation.
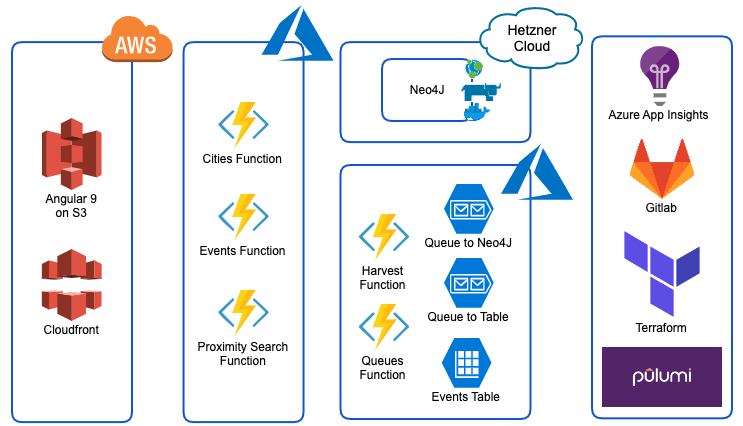
- Note: The goal of the 2020 architecture redesign was to use as many serverless technologies as possible for Harvee
- As with the previous version the frontend is built using Angular (updated to version 9). It is hosted in an Amazon S3 bucket and served via a Amazon Cloudfront distribution.
- All APIs have been migrated from self-hosted Python (Flask, Django, Docker, Rancher) webservices to Azure Functions
- There is only one actual server still used for Harvee. Deployed in Hetzner Cloud it is hosting a Neo4J graph database.
- Capturing and processing the event data is also done using Azure Functions. A harvest function (executed by a time trigger) calls the webservice from a local event website to collect the events. Events are then put onto Azure Queue Storage queues. Additional functions triggered by messages being put onto these queues are consuming the events, are enriching them (by sending the event venues to Foursquare in order to get their geo coordinates) and are finally storing them in an Azure Table Storage table. A subset of the event data (primarily the relationship between events and venues) is ingested into the Neo4j Graph Database in order to allow for a geo search.
- For monitoring of my Azure Functions I am relying on log and exception monitoring provided by Azure Application Insights
- All of the infrastructure is deployed as code using Pulumi. The application (Azure functions) is also deployed through Pulumi. SSL certificates are required in order to enable SSL endpoints with custom hostname bindings for the functions. The certificates are provisioned through Terraform using the Let’s Encrypt/ACME provider and stored in an Azure KeyVault, which gets consumed again from Pulumi.
- Most of the code is now written in Typescript. The new versions of Angular are based on it and it feels like Pulumi is treating it better than e.g. Python. Also it seems that support in Azure Functions is better for Typescript than it is for Python at the moment.
- All code is stored in Gitlab. At this point all code deployments are still being done manually.